
The table on the right was directly lifted from a report exploring the scalability of a fairly traditional client-server application on the Sun Fire E6900 and E25K platforms.
The system boards in both machines are identical, only the interconnects differ. Each system board has four CPU sockets, with a dual-core CPU in each, yielding a total of eight virtual processors per board.
The application client is written in COBOL and talks to a multithreaded C-ISAM database on the same host via TCP/IP loopback sockets.
The workload was a real world overnight batch of many “read-only” jobs run 32 at a time.
The primary metric for the benchmark was the total elapsed time. A processor set was used to contain the database engine, with no more than eight virtual processors remaining for the application processes.
The report concludes that the E25K’s negative scaling is due to NUMA considerations. I felt this had more to do with perceived “previous convictions” than fact. It bothered me that the E6900 performance had not been called into question at all or explored further.
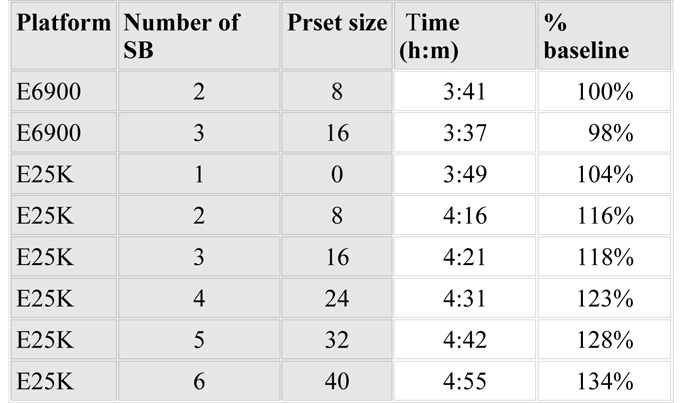
The situation is made a little clearer by plotting the table as a graph, where the Y axis is a throughput metric rather than the total elapsed time.
Although the E25K plot does indeed appear to show negative scalability (which must surely be somehow related to data locality), it is the E6900 plot which reveals the real problem.
The most important question is not “Why does the E25K throughput drop as virtual processors are added?” but rather “Why does the E6900 hardly go any faster as virtual processors are added?”
Of course there could be many reasons for this (e.g. “because there are not enough virtual processors available to run the COBOL client”).
However, further investigation with the prstat utility revealed severe thread scalability bottlenecks in the multithreaded database engine.
Using prstat’s -m and -L flags it was possible to see microstate accounting data for each thread in the database. This revealed a large number of threads in the LCK state.
Some very basic questions (simple enough to be typed on a command line) were then asked using DTrace and these showed that the “lock waits” were due to heavy contention on a few hot mutex locks within the database.
Many multithreaded applications are known to scale well on machines such as the E25K. Such applications will not have highly contended locks. Good design of data structures and clever strategies to avoid contention are essential for success.
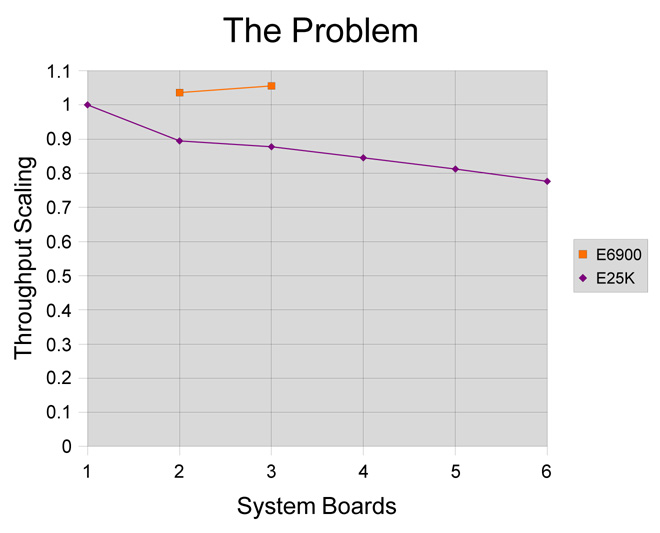
This second graph may be purely hypothetical but it does indicate how a carefully written multithreaded application’s throughput might be expected to scale on both the E6900 and the E25K (taking into account the slightly longer inter-board latencies associated with the latter).
The graph also shows that something less that perfect scalability may still be economically viable on very large machines — i.e. it may be possible to solve larger problems, even if this is achieved with less efficiently.
As an aside, this is somewhat similar to the way in which drag takes over as the dominant factor limiting the speed of a car — i.e. it may be necessary to double the engine size to increase the maximum speed by less than 50%.
Working with the database developer it was possible to use DTrace to begin “peeling the scalability onion” (an apt metaphor for an iterative process of diminishing returns — and tears — as layer after layer of contention is removed from code).
With DTrace it is a simple matter to generate call stacks for code implicated in heavily contended locks. Breaking such locks up and/or converting mutexes to rwlocks is a well understood technique for retrofitting scalability to serialised code, but it is beyond the scope of this post. Suffice it to say that some dramatic results were quickly achieved.
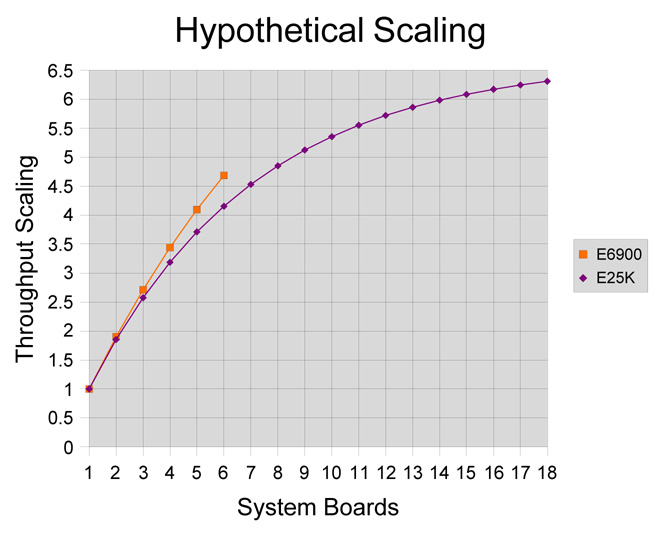
Using these techniques the database scalability limit was increased from 8 to 24 virtual processors in just a matter of days. Sensing that the next speed bump might take a lot more effort, some other really cool Solaris innovations were called on to go the next step.
The new improved scalable database engine was now working very nicely alongside the COBOL application on the E25K in the same processor set with up to 72 virtual processors (already somewhere the E6900 could not go).
For this benchmark the database consisted of a working set of about 120GB across some 100,000 files. With well in excess of 300GB of RAM in each system it seemed highly desirable to cache the data files entirely in RAM (something which the customer was very willing to consider).
The “read-only” benchmark workload actually resulted in something like 200MB of the 120GB dataset being updated each run. This was mostly due to writing intermediate temporary data (which is discarded at the end of the run).
Then came a flash of inspiration. Using clones of a ZFS snapshot of the data together with Zones it was possible to partition multiple instances of the application. But the really cool bit is that ZFS snapshots are almost instant and virtually free.
ZFS clones are implemented using copy-on-write relative to a snapshot. This means that most of the storage blocks on disk and filesystem cache in RAM can be shared across all instances. Although snapshots and partitioning are possible on other systems, they are not instant, and they are unable to share RAM.
The E25K’s 144 vitual processors (on 18 system boards) were partitioned into a global zone and five local zones of 24 virtual processors (3 system boards) each. The database was quiesced and a ZFS snapshot taken. This snapshot was then cloned five times (once per local zone) and the same workload run against all six zones concurrently (in the real world the workload would also be partitioned).
The resulting throughput was nearly five times that of a single 24 virtual processor zone, and almost double the capacity of a fully configured E6900.
All of the Solaris technologies mentioned in this posting are pretty amazing in their own right. The main reason for writing is to underline how extremely powerful the combination of such innovative technologies can be when applied to real world problems. Just imagine what Solaris could do for you!
Solaris: the whole is greater than the sum of its parts.
Technorati Tags: OpenSolaris, Solaris, ZFS, Zones, DTrace