
I’ve just read a couple of intriguing posts which discuss the possibility of hosting UFS filesystems on ZFS zvols. I mean, who in their right mind…? The story goes something like this …
# zfs create tank/ufs
# newfs /dev/zvol/rdsk/tank/ufs
# mount /dev/zvol/dsk/tank/ufs /ufs
# touch /ufs/file
# zfs snapshot tank/ufs@snap
# zfs clone tank/ufs@snap tank/ufs_clone
# mount /dev/zvol/dsk/tank/ufs_clone /ufs_clone
# ls -l /ufs_clone/file
Whoopy doo. It just works. How cool is that? I can have the best of both worlds (e.g. UFS quotas with ZFS datapath protection and snapshots). I can have my cake and eat it!
Well, not quite. Consider this variation on the theme:
# zfs create tank/ufs
# newfs /dev/zvol/rdsk/tank/ufs
# mount /dev/zvol/dsk/tank/ufs /ufs
# date >/ufs/file
# zfs snapshot tank/ufs@snap
# zfs clone tank/ufs@snap tank/ufs_clone
# mount /dev/zvol/dsk/tank/ufs_clone /ufs_clone
# cat /ufs_clone/file
What will the output of the cat(1) command be?
Well, every time I’ve tried it so far, the file exists, but it contains nothing.
The reason for this is that whilst the UFS metadata gets updated immediately (ensuring that the file is created), the file’s data has to wait a while in the Solaris page cache until the fsflush daemon initiates a write back to the storage device (a zvol in this case).
By default, fsflush will attempt to cover the entire page cache within 30 seconds. However, if the system is busy, or has lots of RAM — or both — it can take much longer for the file’s data to hit the storage device.
Applications that care about data integrity across power outages and crashes don’t rely on fsflush to do their dirty (page) work for them. Instead, they tend to use raw I/O interfaces, or fcntl(2) flags such as O_SYNC and O_DSYNC, or APIs such as fsync(3C), fdatasync(3RT) and msync(3C).
On systems with large amounts of RAM, the fsflush daemon can consume inordinate amounts of CPU. It is not uncommon to see a whole CPU pegged just scanning the page cache for dirty pages. In configurations where applications take care of their own write flushing, it is considered good practice to throttle fsflush with the /etc/system parameters autoup and tune_t_fsflushr. Many systems are configured for fsflush to take at least 5 minutes to scan the whole of the page cache.
From this is it clear that we need to take a little more care before taking a snapshot of a UFS filesystem hosted on a ZFS zvol. Fortunately, Solaris has just want we need:
# zfs create tank/ufs
# newfs /dev/zvol/rdsk/tank/ufs
# mount /dev/zvol/dsk/tank/ufs /ufs
# date >/ufs/file
# lockfs -wf
# zfs snapshot tank/ufs@snap
# lockfs -u
# zfs clone tank/ufs@snap tank/ufs_clone
# mount /dev/zvol/dsk/tank/ufs_clone /ufs_clone
# cat /ufs_clone/file
Notice the addition of just two lockfs(1M) commands. The first blocks any writers to the filesystem and causes all dirty pages associated with the filesystem to be flushed to the storage device. The second releases any blocked writers once the snapshot has been cleanly taken.
Of course, this will be nothing like as quick as the initial example, but at least it will guarantee that you get all the data you are expecting. It’s not just no data we should be concerned about, but also stale data (which is much harder to detect).
I suppose this may be a useful workaround for folk waiting for some darling features to appear in ZFS. However, don’t forget that “there’s no such thing as a free lunch”! For instance, hosting UFS on ZFS zvols will result in the double caching of filesystem pages in RAM. Of course, as a SUNW^H^H^H^HJAVA stock holder, I’d like to encourage you to do just that!
Solaris is a wonderfully well-stocked tool box full of the great technology that is ideal for solving many real world problems. One of the joys of UNIX is that there is usually more than one way to tackle a problem. But hey, be careful out there! Make sure you do a good job, and please don’t blame the tools when you screw up. A good rope is very useful. Just don’t hang yourself!
Technorati Tags: OpenSolaris, Solaris, ZFS

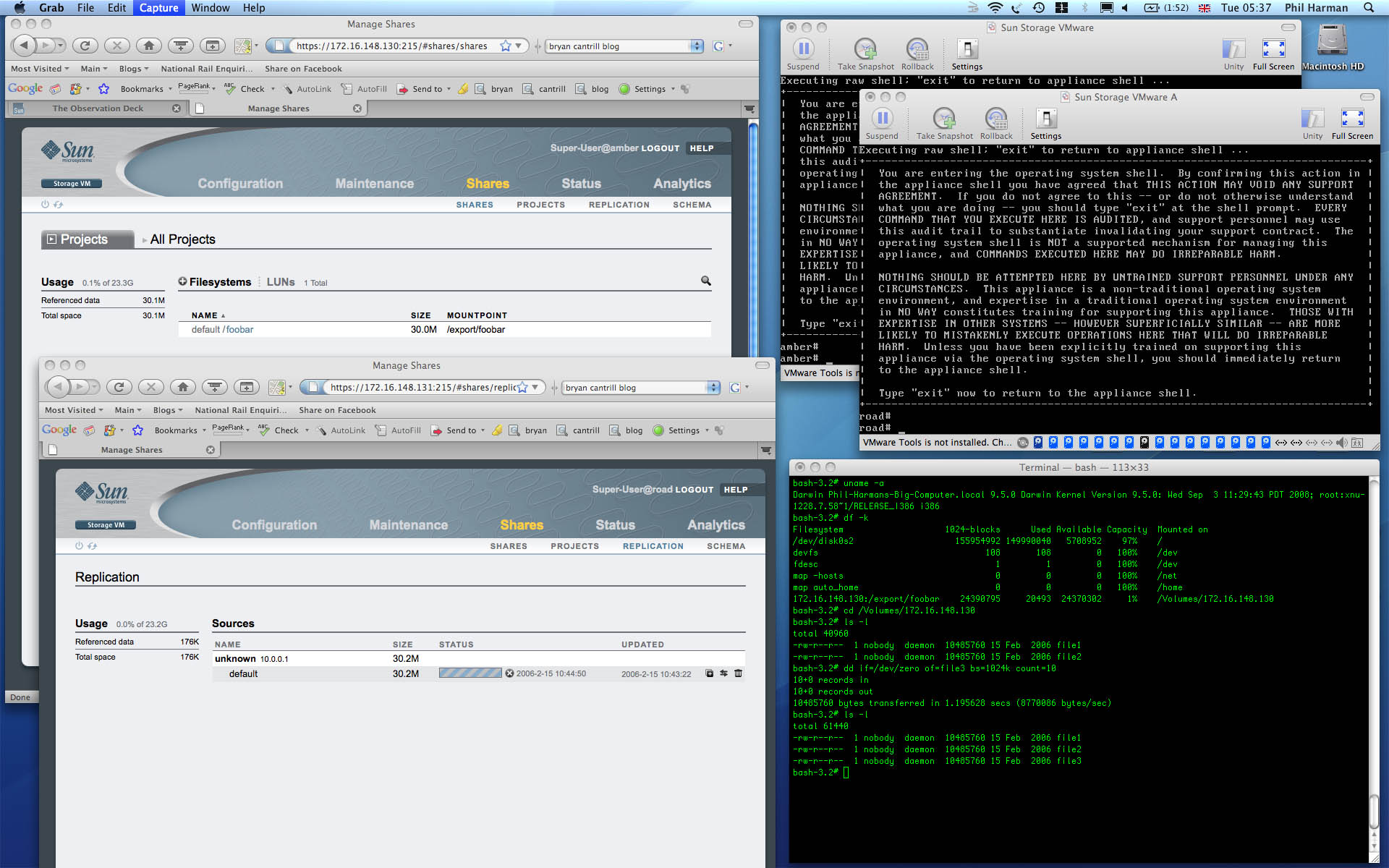
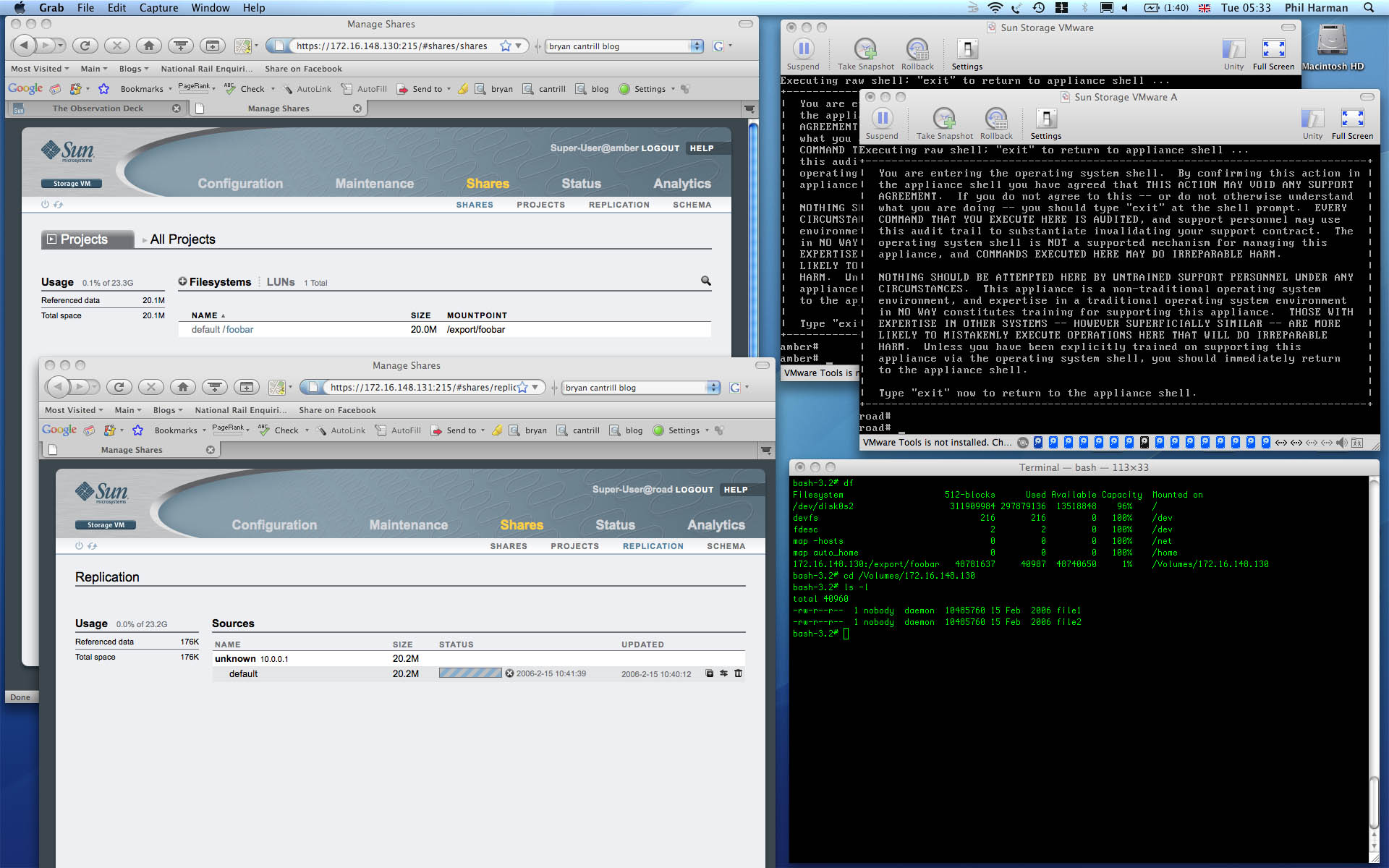 I was there when they launched the Sun Storage 7000 Unified Storage Systems (“there” being the CEC conference in Las Vegas). Within an hour of the launch I had downloaded the Sun Unified Storage Simulator for VMware Fusion and started playing with this ultra-cool software stack on my MacBook Pro.
I was there when they launched the Sun Storage 7000 Unified Storage Systems (“there” being the CEC conference in Las Vegas). Within an hour of the launch I had downloaded the Sun Unified Storage Simulator for VMware Fusion and started playing with this ultra-cool software stack on my MacBook Pro.


{kind=link}
{kind=link}