
I recently bought a new Apple MacBook Pro. It’s faster, lighter, cooler, smaller than the one it is replacing, and all connectivity is via USB-C. This is a good thing. Like many, I was skeptical about the usefulness of the Touch Bar, but I’m now convinced.
It wasn’t cheap, but it doesn’t end there. I have been known to leave my power supply at home when visiting customers, so I like to keep a second PSU and leads in my computer bag at all times.
My new MBP has four USB-C ports and uses an 87W USB-C Power Adaptor. At £79, they aren’t cheap either. However, this does not include the required UCB-C Charge Cable, which costs a further £19.
There’s more. The PSU comes with a fused UK BS1363 adaptor. If you want the extension cable that used to be supplied with the previous generation products, that’s extra too.
So, I thought I’d shop around for the best credible deal I could find. But as I’d heard rumours of potentially dangerous, fake, knock-off Apple goods, I thought I’d play it safe by buying from a high street retailer.
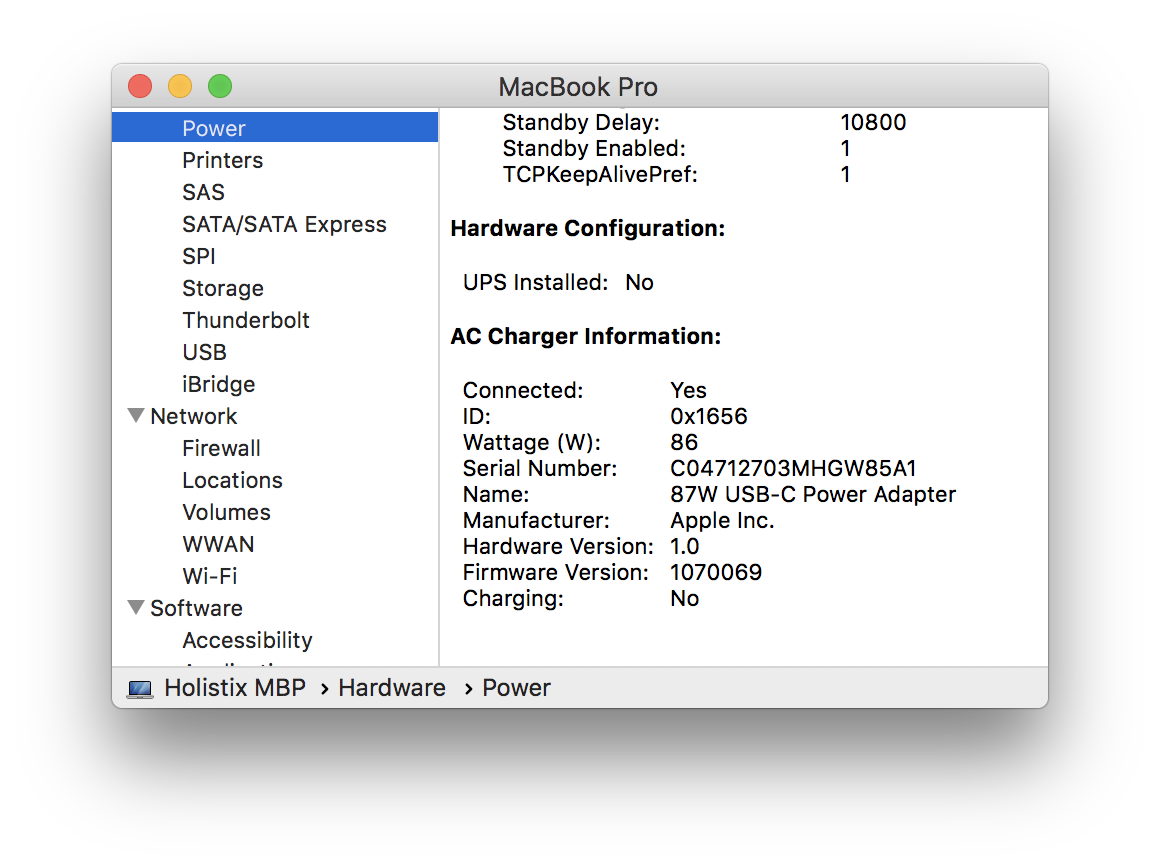
I should have just paid the “genuine” price and moved on. Here’s what System Report shows for the PSU and USB-C cable that came “bundled” with the MBP bought from an authorised Apple Premium Reseller in town…
And here’s the same report for the PSU and USB-C cable I bought from an “other” independent computer sales and repair shop in another town…
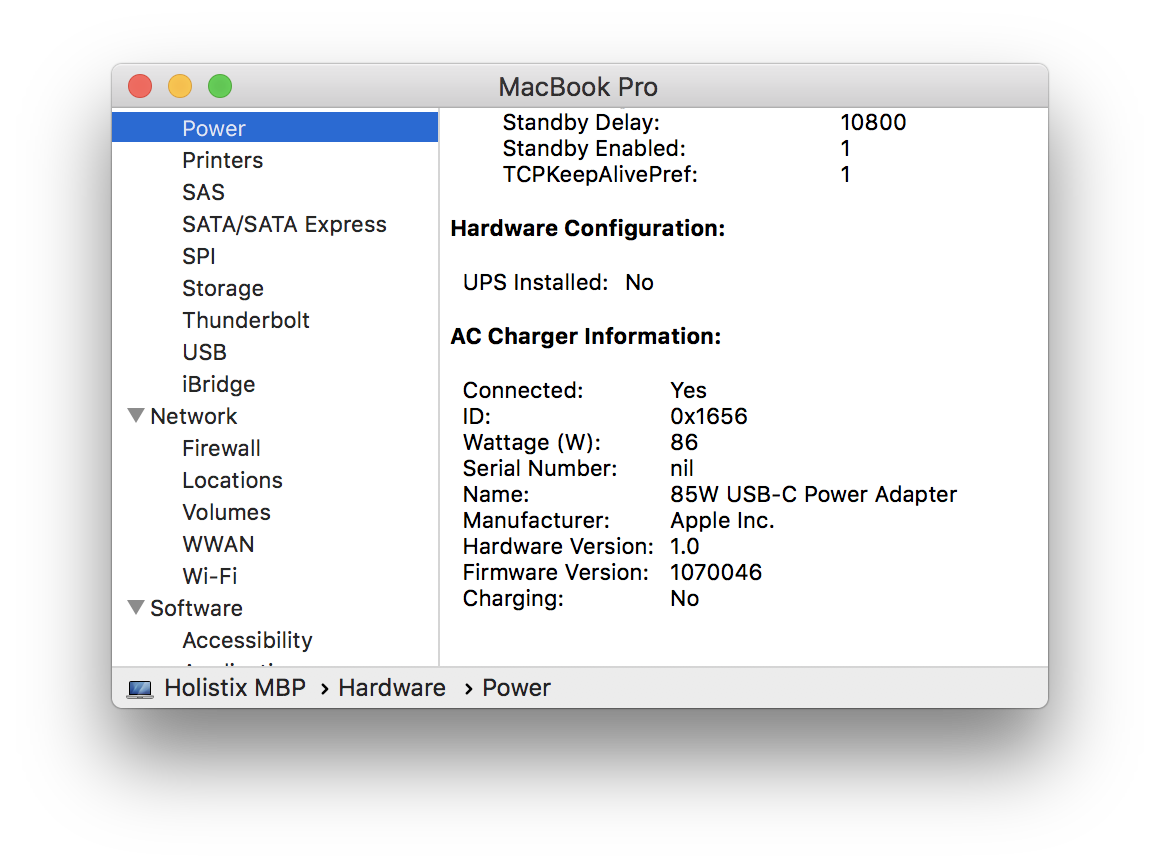
Notice that the products show the same values for ID, Wattage, etc., but different values Serial Number, Name and Firmware Version. Indeed, the “other” PSU appears to have no serial number. More on this in a moment.
The two USB-C cables are the same length, but look and feel very different. With some googling around, I found that Apple had some issues with early versions of the cable…
A limited number of Apple USB-C charge cables that were included with MacBook computers through June 2015 may fail due to a design issue. As a result, your MacBook may not charge or only charge intermittently when it’s connected to a power adapter with an affected cable.
…Affected cables have “Designed by Apple in California. Assembled in China.” stamped on them. New, redesigned cables include a serial number after that text.
Here’s the printing stamped on my two cables (“bundled” left, “other”, right) …

So, at best the “other” cable is one of the ones which Apple would have recalled. But how else do they differ? Here’s what they look like, and how they weigh-in (again, “bundled” left, “other”, right) …

Although the cables are the same length, the “bundled” cable is thicker, heavier, and coils more tidily. But does this matter?
Well, some products sold as “genuine” certainly seem to matter in Apple . In October 2016, they filed a lawsuit after finding that 90% of 1000 “genuine” chargers they had bought from Amazon were fake. It also mattered to a blogger who nearly set his hotel room on fire with a fake charger.
Remember that both solutions claim to supply 86 Watts? Presumably the “other” cable is lighter because it has less metal. So is it actually able to safely supply 86 Watts all day and all night long? My “bundled” PSU doesn’t think so …
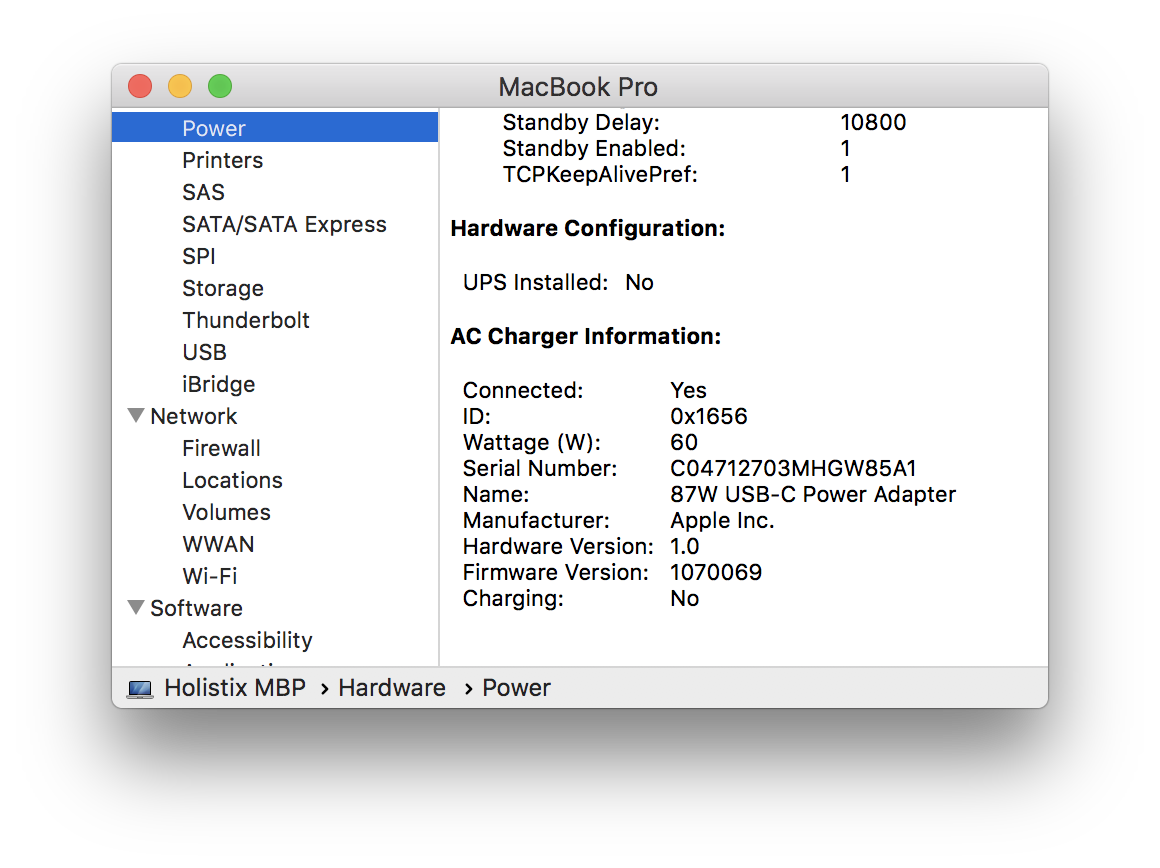
With the “bundled” PSU the MBP limits the current to 60 Watts with the “other” cable. This is beginning to sound like a good idea. Indeed, apart from generating the above screen grabs, I haven’t been using the “other” PSU or cable at all.
So, how can you tell that you’ve got a “genuine” Apple PSU? Well, without opening them, up (and voiding the warranty) it’s hard to tell, though someone has done so for other models.
But there are other ways to tell them apart …




In short, the screen printing is clearer, and the seams are tighter. In the last photo above, notice that the fit of the USB-C cut-away is pretty sloppy.
But there’s also one other major difference. The “bundled” PSU’s serial number is printed deep inside the power connector…

This seems to be a new move by Apple, as previous PSUs had the serial number on a sticky label next to the retaining pin. So at best, I think my “other” PSU is an early edition. But then, it’s strange that it has no serial number at all.
The “other” PSU is also about 4 grams lighter than the “bundled” one. What only 4 grams? Yes, but without opening it up, it’s difficult to know, though fakers have been known to add ballast.
However, I do think there is another way to tell them apart. Ladies and gentlemen, I give you “The Knock-off Knock-off”…
I tried this test a number of times, switching the PSUs around in my hand. To my ears, at least, the “other” PSU (the second one) sounds a little more hollow than the “bundled” one.
When I first spoke on the phone (before visiting the shop), when three of us visited the shop, and in email correspondence since, the independent retailer has insisted that his products are “genuine”…
We only sell genuine parts, these are not retail boxed hence why the serial number does not match within an Apple store, as when you purchase retail boxed products, the large extra fee you pay is to allow you to be on their system and be able to take a faulty product back to any Apple store, anywhere in the world. If you are not happy with your purchase then by all means please bring back to us and we will refund you no problem.
I have since bought another PSU and cable in “retail boxes” from our local Apple Premium Reseller. Unlike the “other” products purchased from the independent retailer, the “retail boxed” and “bundled” products are identical in every detail (except for their serial numbers, of course).
One consolation is that the Apple charger is able to charge and/or power just about any other USB-C device (as well as iPhones and iPads via a UCB-C to Lightning cable). I’m convinced that being all-USB-C is a really good thing.
But I’m not sure what to do next. I’m NOT going to name and shame my source in public. I have to assume that he was acting in good faith. Perhaps I should just return the goods for the promised refund? However, I’d hate to think that someone else might end pulling 87 Watts through a substandard cable.
Suggestions?


